Output Schema
 When making a request to a document, your input and output data will be in JSON format. The structure of this data is defined by the document’s input and output schema. The input schema specifies the format and types of data that the document expects, while the output schema defines the format and types of data that the document will return after processing.
You can find the input and output schema for each document on the Logic Dashboard. Click on your document, then click on the
When making a request to a document, your input and output data will be in JSON format. The structure of this data is defined by the document’s input and output schema. The input schema specifies the format and types of data that the document expects, while the output schema defines the format and types of data that the document will return after processing.
You can find the input and output schema for each document on the Logic Dashboard. Click on your document, then click on the Integration tab. The input and output schema will be displayed in the Input Schema and Output Schema sections, respectively.
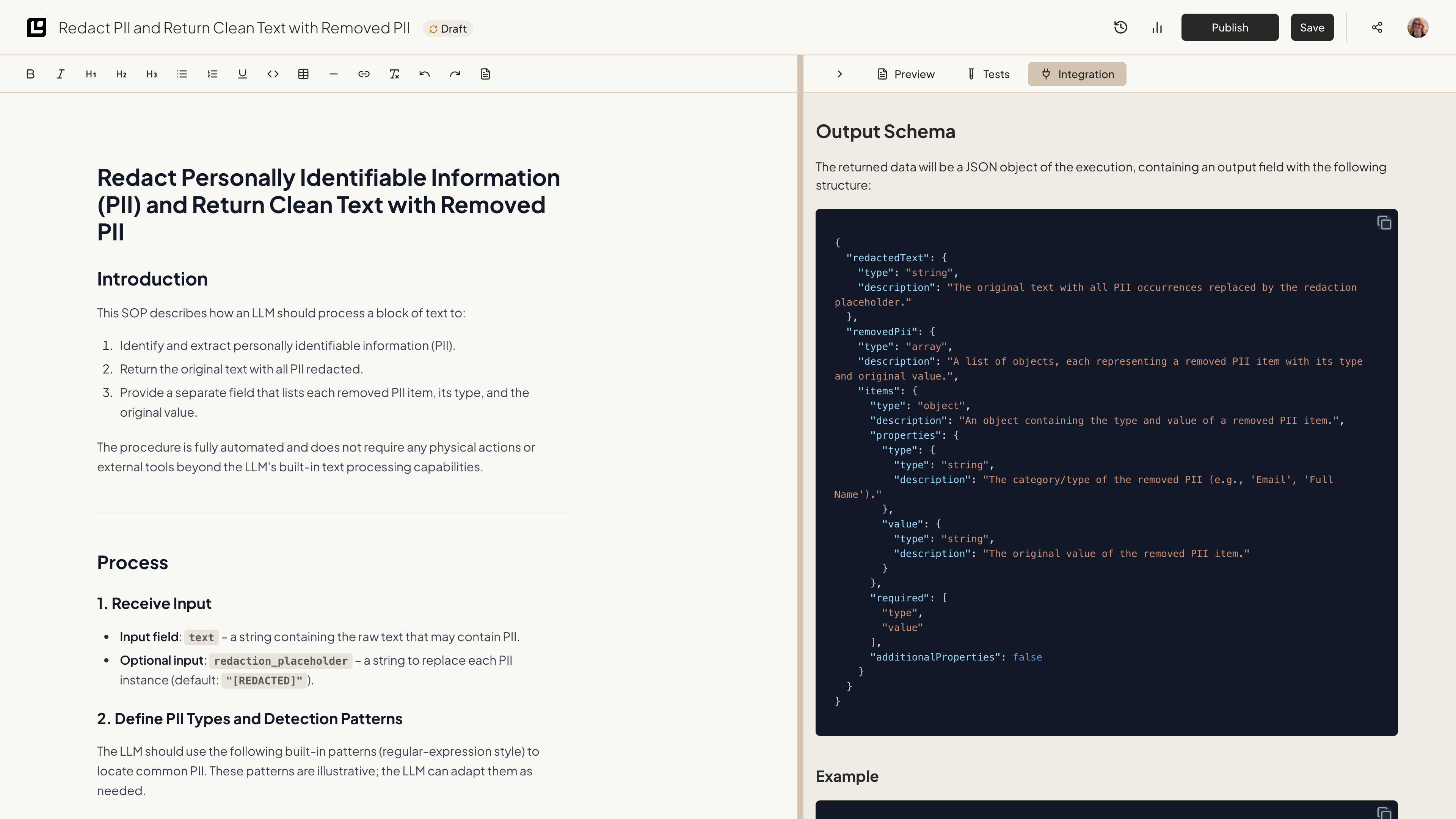
For this example, we will be using the Redact PII document. This document is designed to redact personally identifiable information (PII) from a given text input.
Output Schema
The returned data will be a JSON object of the execution, containing an output field with the following structure:
{
"redactedText": {
"type": "string",
"description": "The text with all detected PII replaced by appropriate placeholders (e.g., {{ name }}, {{ email }})."
},
"redactedEntities": {
"type": "array",
"description": "A list of entities that were redacted from the original content.",
"items": {
"type": "string",
"description": "A single entity that was redacted from the content."
}
}
}
The output schema will differ depending on your document.
Output Example
{
"redactedText": "{{ name }} emailed me at my personal address: {{ email }}.",
"redactedEntities": ["Steve", "mary@yahoo.com"]
}