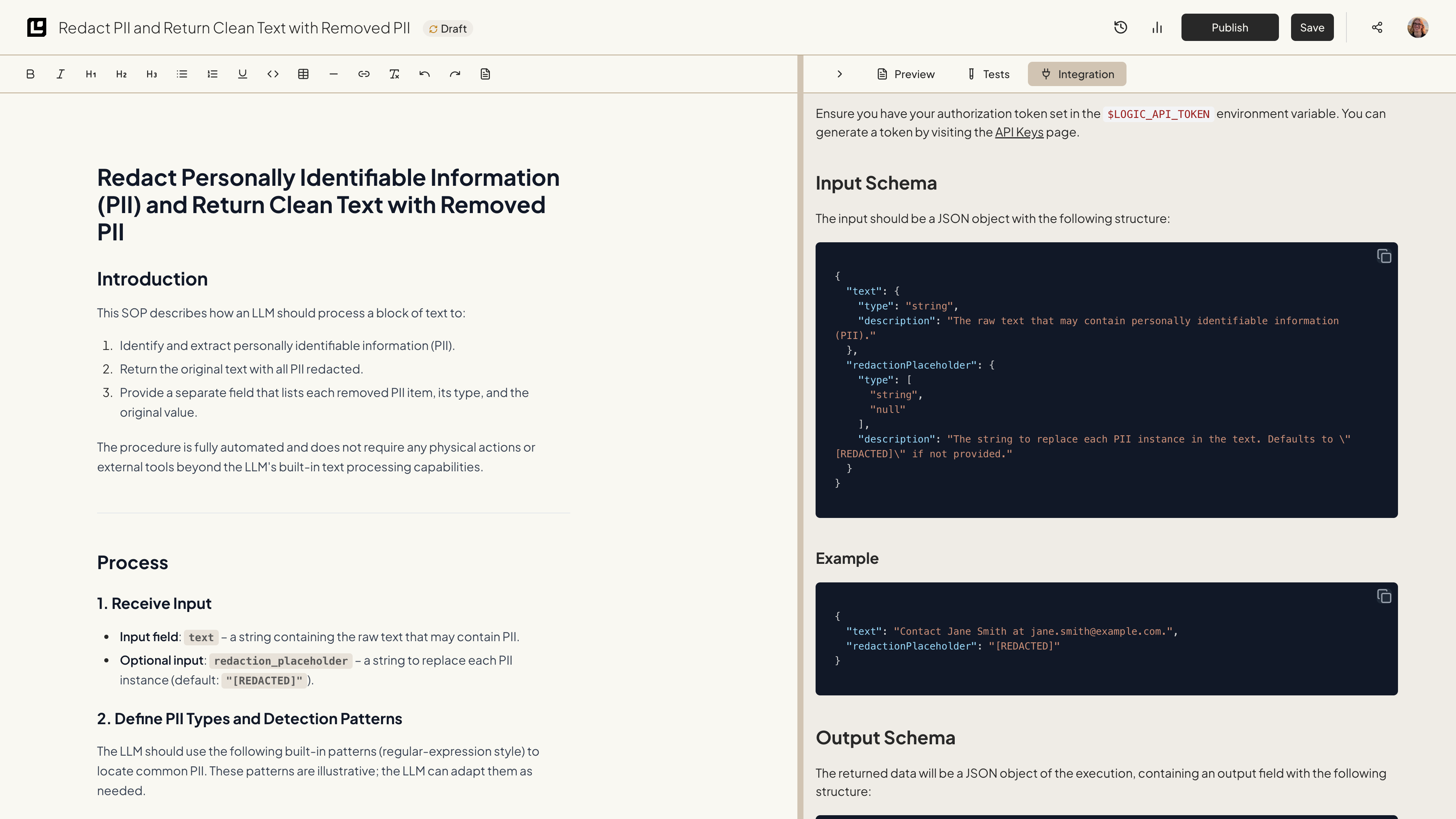
Input Schema
Integration tab. The input and output schema will be displayed in the Input Schema and Output Schema sections, respectively.
For this example, we will be using the Redact PII document. This document is designed to redact personally identifiable information (PII) from a given text input.
Input Schema
The input should be a JSON object with the following structure:content field. The content field is a string that contains the PII to be redacted. The document will process this text and identify any PII present, such as names, email addresses, phone numbers, etc. It will remove them from the text and return them in a separate array.
The input schema will differ depending on your document.
Input Example
In this case, the input is a string containing text. When writing your
document, you can also use images and other files as inputs, either as a URL
or base64-encoded string.